




Google has indexed billions of web pages. In fact, according to Statistic Brain - Google had 67,000,000,000 (67 Billion) pages indexed in 2014. But while, that’s an impressive number - it still means that Google has yet to live up to it’s name.Google originally got it’s name from the math word, googol, which is a number. A really big number. A googol is a 1 with 100 zeros after it. It looks like this:
10,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,
000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000
But usually we just write it the way Google does in its calculator:
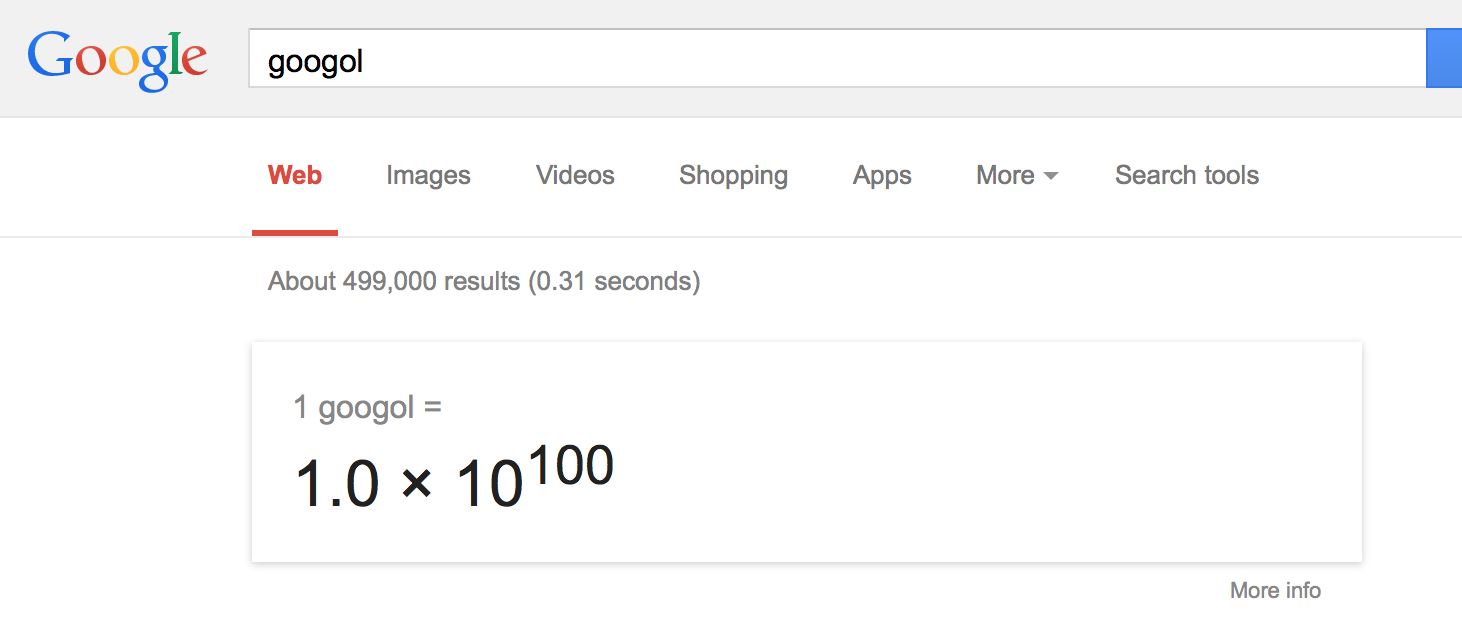
So - how long will it take for Google to index 1 googol web pages? A lot longer than you think. If you hate math, then you can skip to the bottom section and I will give you the answer - it won't happen in your lifetime.
Calculating the growth rate
Figuring out how many pages Google has indexed is annoying - mostly because they don’t exactly make that public knowledge. I did way too much research on this; and then gave up. Thankfully I found Wonder and was able to have them do the research for me. After all the research, I eventually had to just choose one of the estimates and run with it or I would lose my sanity. The data set that I chose to work with was the one I quoted above by Statistic Brain.*
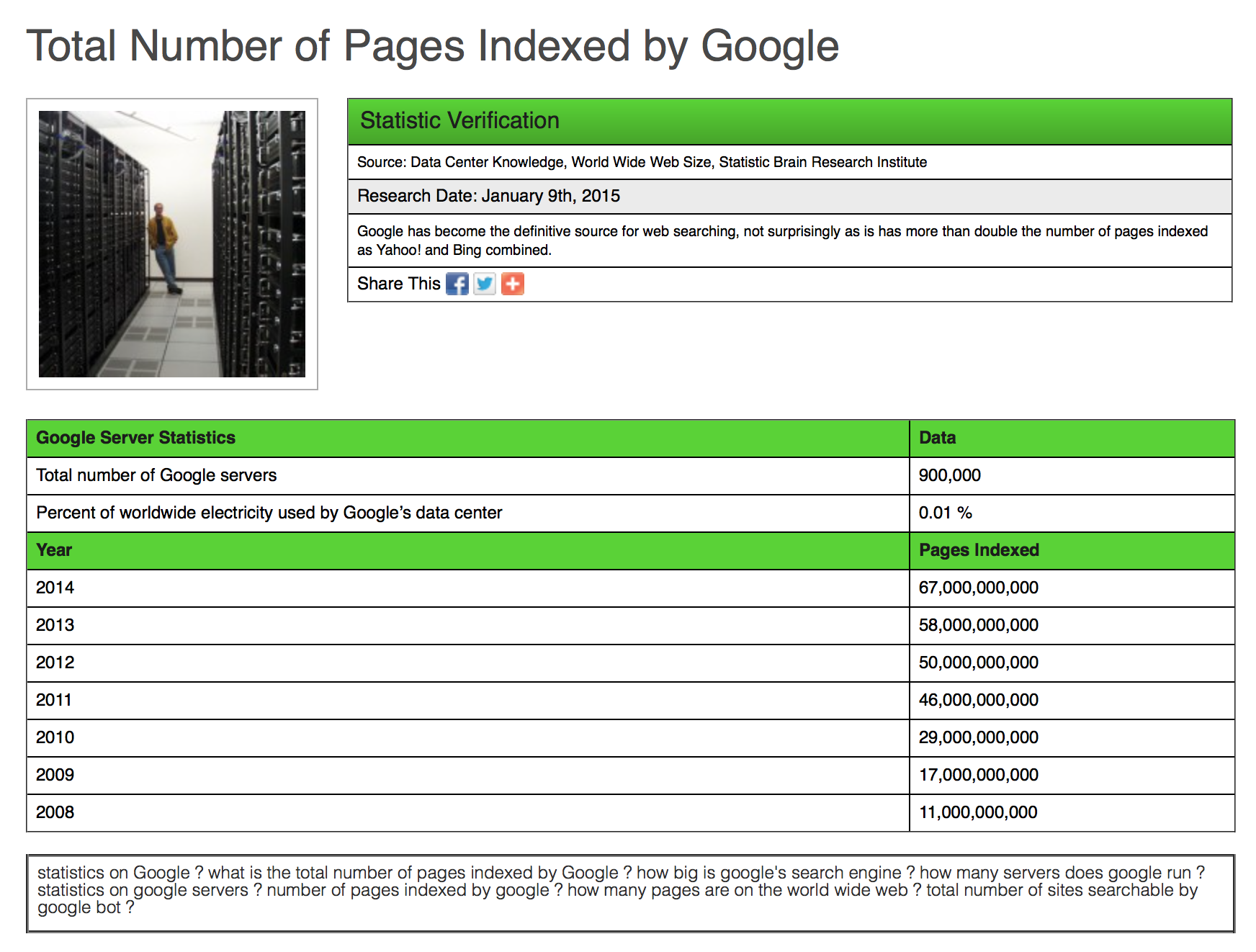
I calculated the average growth rate of these numbers using the formula:[caption id="attachment_424" align="aligncenter" width="354"]
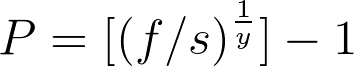
P = [(f/s)^(1/y)] – 1[/caption]Where f = 67 (the ending number of pages indexed with the zeros left off), s = 11 (the beginning number of pages indexed, again with the zeros left off) and y = 6 (the number of years). I actually performed these calculations in the Google search bar just for the irony.
The end result is P = 35% rounded up.
But - the problem with this is that it assumes Google can continue to keep up a 35% growth rate for a really really long time - which is unlikely. So to be fair, I also figured out what the lowest rate of growth was for Google over the last few years so we can see two options - one where Google goes on an indexing spree and maintains 35% growth rate, and one where Google just maintains a more realistic growth rate (which will still become increasingly hard with each following year).The slowest indexing growth rate Google saw over that data set was between the year 2011 and 2012 - which looks like this:
50,000,000,000 / 46,000,000,000 = 4,000,000,000
4,000,000,000 / 46,000,000,000 = 0.08695652
Which is 8.7% when converted and rounded up.
I have a headache, are we there yet?

In order to figure out the year that Google would actually index 1 googol web pages, we would need to use a formula like this:[caption id="attachment_425" align="aligncenter" width="700"]
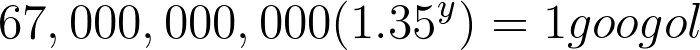
67,000,000,000 (1.35^y) = 1 googol[/caption]Now - I’m not exactly a math professor so I might not do this the fastest way - just the way that makes sense to me. Remember, we have to get our unknown variable all by itself - which in our case is y. So we divide both sides of our equation by 67 Billion and we get this:[caption id="attachment_426" align="aligncenter" width="686"]
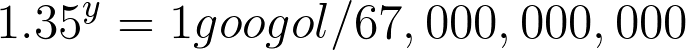
1.35^y = 1 googol / 67 Billion[/caption]Getting closer. This is the tricky part - and the part that I had to have a friend look at to make sure I was correct (so if I’m still wrong - blame my math friend, not me). In order to get y in a position that is no longer an exponent, we need to use logarithms. As scary and frustrating as logarithms may be for many of you, there is actually a group of psychologists that believe we naturally do math logarithmically before learning to count linearly. Anyway, this is what our equation looks like now:[caption id="attachment_427" align="aligncenter" width="815"]
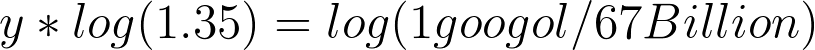
y log(1.35) = log (1 googol / 67 Billion)[/caption]OK, let’s keep moving. Our next step (and final step for getting y all by itself) is to divide both sides of our equation by log(1.35). The new equation looks like this:[caption id="attachment_428" align="aligncenter" width="791"]
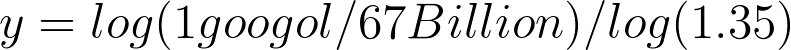
y = log(1 googol / 67 Billion) / log(1.35)[/caption]Now this is the easy part. To figure out how much 1 googol / 67 Billion is - I simply typed it into Google. It equaled 1.4925373e+89 - which is obviously rounded up quite a bit - but that is the best number I could get from using a calculator and will probably be accurate enough for what we’re doing.[caption id="attachment_429" align="aligncenter" width="741"]
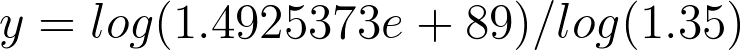
y = log(1.4925373e+89) / log(1.35)[/caption]Wait. Back up a bit. What the heck does the e mean in that number? You can think of the e as basically just meaning "exponent". Another way that we could write that number is 1.4925373x10^89. And lastly, another way to write that would be:
149,253,730,000,000,000,000,000,000,000,000,000,000,000,000,000,
000,000,000,000,000,000,000,000,000,000,000,000,000,000
Next step then is to figure out what log(1.4925373e+89) and log(1.35) equal. Again, according to Google, they equal 89.1739251934 and 0.13033376849 respectively. So now our equation looks like this:[caption id="attachment_430" align="aligncenter" width="725"]
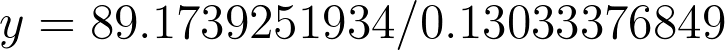
y = 89.1739251934 / 0.13033376849[/caption]Pop that bad boy into Google and you finally have your answer.[caption id="attachment_431" align="aligncenter" width="394"]
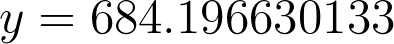
y = 684.196630133[/caption]In case you forgot y = years. So approximately 684 years from the end of 2014 which would be the year, 2698, we should expect Google to finally live up to it’s namesake and have 1 googol pages indexed.
"If we assume a 35% compounded annual growth, Google will index 1 googol web pages in the year 2698."
But that was assuming the crazy fast rate of 35% growth year after year for the next 684 years. If we wanted to be perfectly accurate, we would have to show that growth rate slowing down year after year because it would likely become more and more difficult to grow that same rate year after year. But then again, maybe technology continues to grow just as fast and they find that it’s not difficult to maintain that rate.Either way, here is the math for the slower rate we came up with earlier of 8.7% compounded annual growth rate. We would start off with almost the same thing as above, the only difference is that we will be multiplying by 1.087 instead of 1.35:[caption id="attachment_432" align="aligncenter" width="725"]
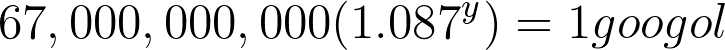
67,000,000,000 (1.087^y) = 1 googol[/caption]I will save you from having to see all the math worked out again. The only different number will be the log(1.087) which equals 0.03622954408. Our final answer using the 8.7% growth rate is:[caption id="attachment_433" align="aligncenter" width="395"]
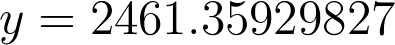
y = 2461.35929827[/caption]Again, y = years, so approximately 2,461 years from the end of 2014 which would be the year, 4476 - which will also be America’s 2700th Anniversary, or its Vigiseptacentennial.
"IF WE ASSUME An 8.7% COMPOUNDED ANNUAL GROWTH, GOOGLE WILL INDEX 1 GOOGOL WEB PAGES IN THE YEAR 4476."
Tangent

So the name for the 1,000th anniversary is the Millenary. But that would mean I would have to figure out how to name the 2.7 thousandth anniversary which seems harder than still going by 100’s.
"So, if I were to name the 2700th anniversary, I would call it the VIGISEPTACENTENNIAL."
Vigi- is from the prefix vigint- Latin for 20, septa- is the Latin prefix we use for 7, and centennial is the word we use for 100 (again from Latin to keep it all consistent).
Back to Google
Google likes to change the very meaning of an already established word. Googol became Google - and now they just created a company called Alphabet. They didn’t even bother changing the spelling this time, which is going to be really confusing teaching my 2-year old about the differences between saying her Alphabet (singing the letters) and using the Alphabet (Google products).Does this matter? No. Not even one bit. But I find it intriguing. If we assume that it will take Google 2,461 years to actually index one googol web pages, then we have to ask ourselves a few other hypothetical questions.
Q. Will Google even exist as a company 2,461 years later?
A. According to Business Insider, most companies are only around for 40-50 years. In that same article they talk about some of the world’s oldest established businesses, including a hotel in Japan that has been operating since the year 705 A.D. Still not 2,461 years - but maybe it tells us that there is a chance.
Q. What will the internet look like in 2,461 years?
A. Seriously, I have no idea. Some guys over at BBC postulated 2 alternate possibilities for the internet in the year 2040. One is happy and bright - quite utopian, while the other is sad and bleak, much more dystopian. David Gelernter at Wired suggests that we are moving from a “space-based” internet to a “time-based” internet. And of course there is all the chatter and growth surrounding the Internet of Things (IoT).
Q. If Google exists 2,461 years later, will they even care about indexing web pages?
A. Google may have started out as a search engine, but they continue to branch out into other things, like Glasses, Cars, and secret stuff. How much will they care about indexing web pages? Probably not that much - it will be perhaps some department in a dusty office in the basement, not even run by human beings anymore - just some automated A.I. program that was last coded in the year 2501.
Q. Why didn't you depreciate the rate of index?
A. Mostly because there is so much that is undeterminable right now. Can the web even grow to a googol web pages? If it can - will it - or will something replace it before then? What if graphene and quantum computers take off - then will Google be able to index even faster instead of slower? There was just too much to really get into it without going off the deep end, so I decided to keep it simple.
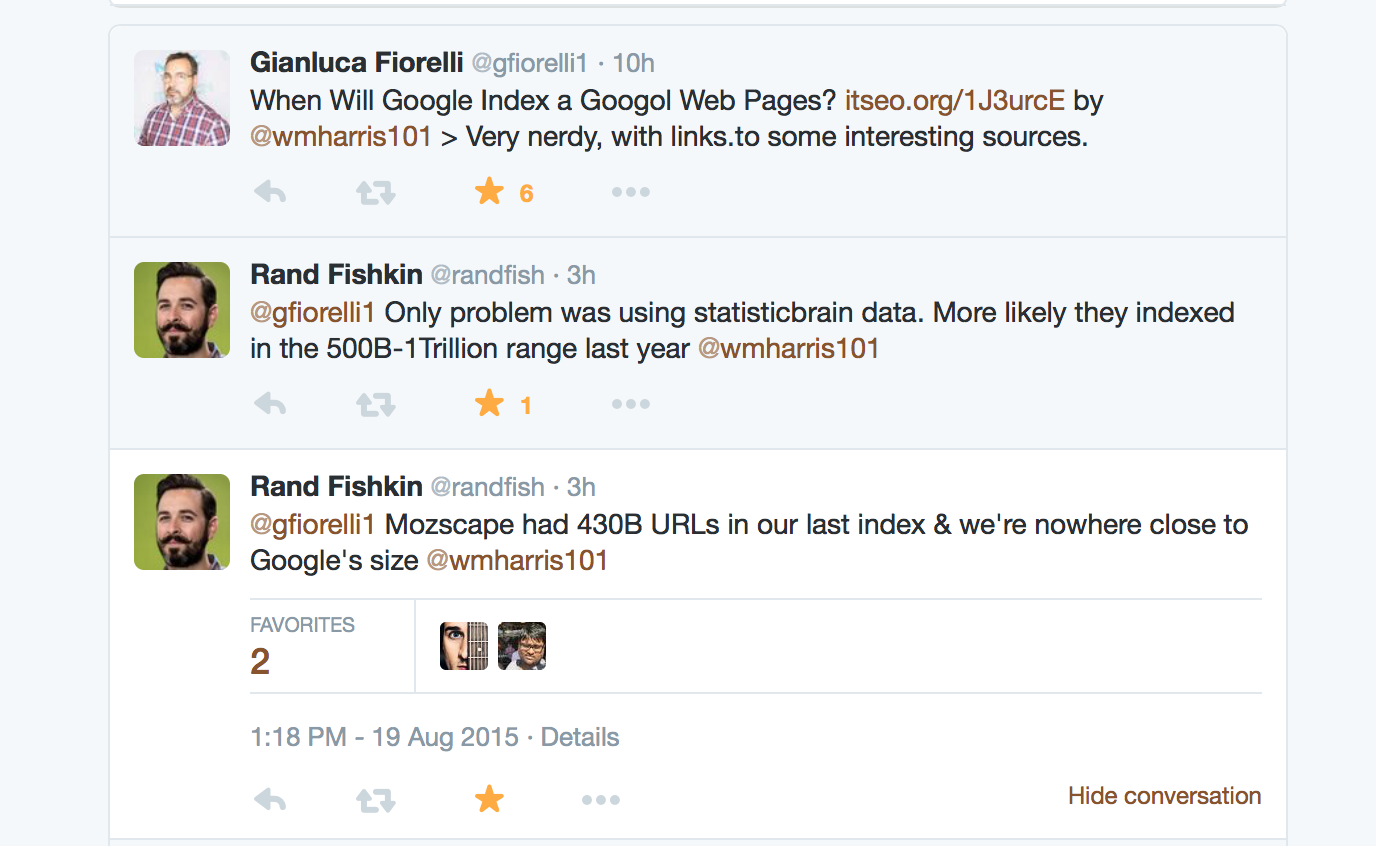
What do you think? What will the internet look like in the year 4476? Will Google still be around?+ Also, if anyone knows Brady Haran from Numberphile - can you get him to find someone that is willing to double check my math? Or maybe even model it better?* Editor's note: I just had a great conversation on Twitter with Gianluca Fiorelli and Rand Fishkin about this post. Rand pointed out that Google likely had closer to 500 Billion to 1 Trillion webpages indexed last year. Rand is a genius and his logic makes sense based on the number of pages Moz has indexed. Regardless, I had to eventually just pick a number that was backed up by a decent resource since no one really knows how many pages Google has indexed. The overall outcome wouldn't change much - it would still take place so many years from now that it's impossible to fathom what the internet will be like. Here's the conversation though for those that are curious.













%201.png)